Connection pooling is a simple technique that can significantly improve the performance of your application. However, to effectively apply and manage connection pooling, it is crucial to understand how it works and how it can be configured.
Quick access:
The Problem
Understanding Database Connection
A database connection is a communication link between a software application and a database. When an application needs to interact with a database to perform operations such as querying or updating data, it establishes a connection. This connection enables the application to send commands to the database and receive the required data in response.
A lifecycle of a database connection involves several steps, including:
- Opening a network connection to the database server.
- Authenticating the user and verifying permissions.
- Handshaking and starting data exchange.
- When the operation is done, tearing down the connection.
The process seems simple, especially when there are a few operations to perform in a short period, until…
Things go intensively
In a real-world scenario, applications demand handling multiple database operations frequently and concurrently. In a naive approach, each operation requires establishing a new connection, which is resource-intensive and time-consuming, so-called “connection overhead”, due to several reasons:
- Handshaking and authentication: This process takes time, especially if done repeatedly for each database operation. Establishing a new connection requires a series of network handshakes and authentication steps, which can reduce dramatically the performance of the application.
- CPU and Memory Overhead: Each connection consumes system resources, including CPU and memory. Creating and destroying connections frequently can lead to resource exhaustion and performance degradation.
- Resource Management: Each active connection consumes resources such as memory and network sockets. Maintaining a large number of idle connections at a time can lead to inefficient resource management, as these resources are repeatedly allocated and deallocated.
Types of Connection Pooling
Connection pooling was invented to address the issues mentioned above, which allows reusing existing connections instead of creating new ones for each operation. Connection pooling can be implemented in different ways depending on whether it is managed by the client application or the server. Both approaches aim to improve performance and resource utilization but operate at different levels and contexts. Let’s explore each type in detail.
Client-side Connection Pooling
Client-side connection pooling, as its name implies, is designed to manage and reuse database connections within a client application, such as a web server or a microservice. The primary goal is to enhance performance and optimize resource utilization on the client side.
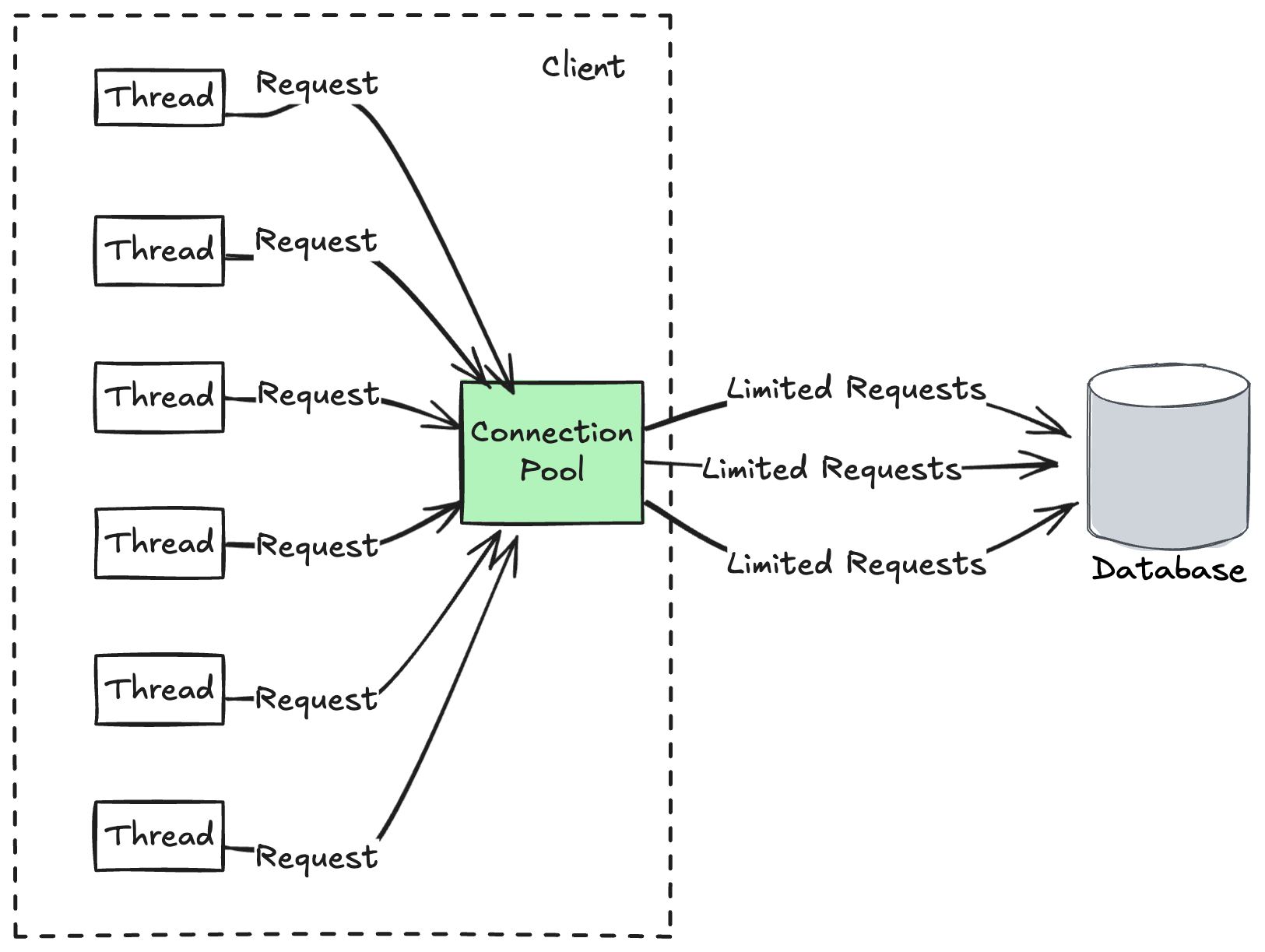
Client-side Connection Pooling Concept
How it Works:
- The client application maintains a pool of database connections.
- When the application needs to execute a database query, it checks out an existing connection from the pool instead of creating a new one.
- After the query is executed, the connection is returned to the pool for future reuse.
Client-side connection pooling offers several benefits, including:
- Reduces the overhead of establishing new database connections.
- Improves the responsiveness of the application by providing quick access to pre-established connections.
- Helps to manage the number of connections to the database, preventing resource exhaustion.
Examples of client-side connection pooling libraries include HikariCP, c3p0 for Java applications, and SQLAlchemy for Python applications.
Server-side Connection Pooling
Server-side connection pooling is managed either by the database server itself or by a middleware component that acts as an intermediary between the client and the database. Its purpose is to efficiently handle multiple incoming connection requests from different clients.
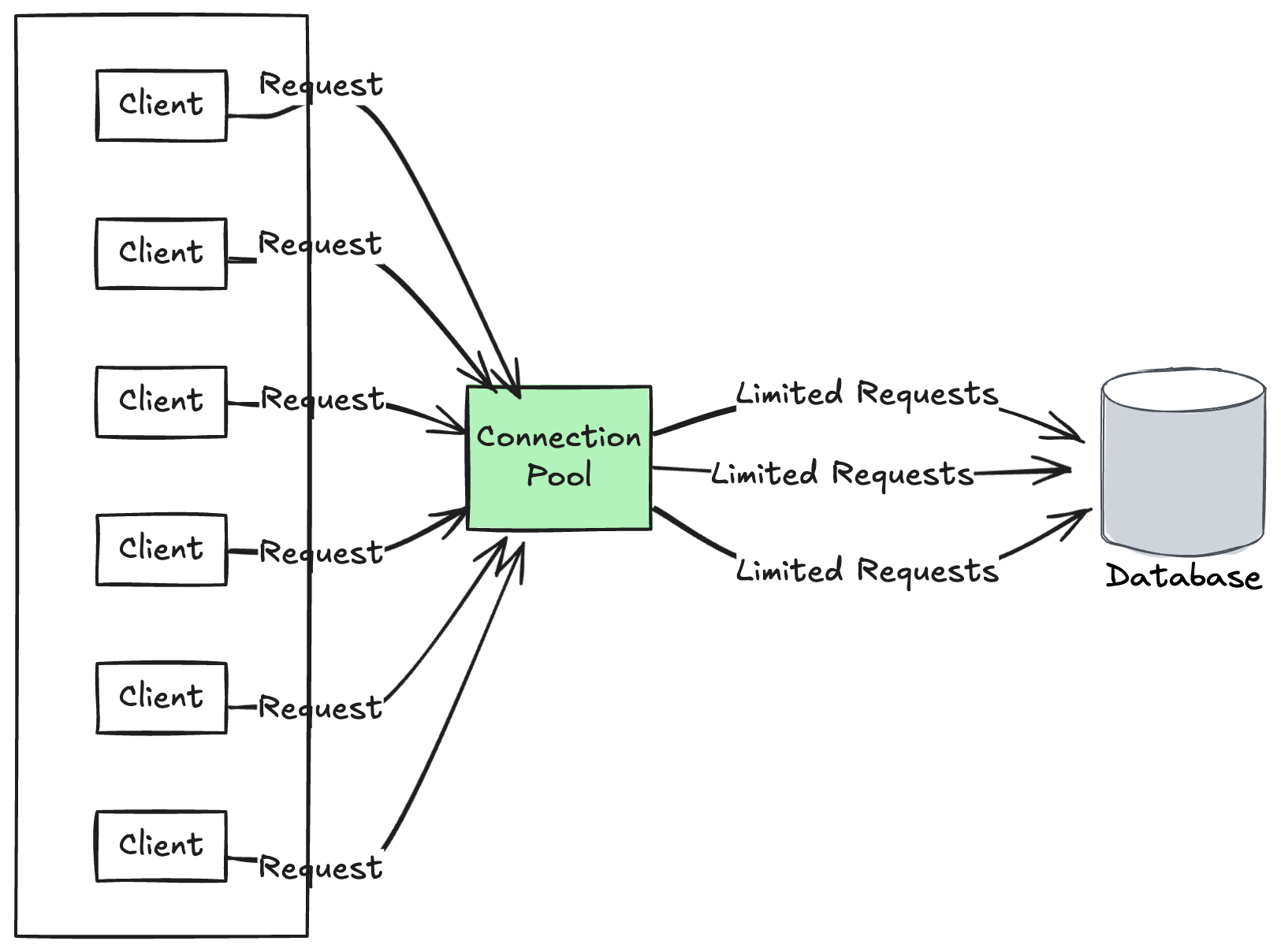
Server-side Connection Pooling Concept as Middleware
How it Works:
- The database server or middleware component maintains a pool of connections.
- When a client requests a connection, the server provides one from the pool.
- After the client is done with the connection, it is returned to the pool.
Examples of server-side connection pooling mechanisms include built-in features in database systems like PostgreSQL’s pgbouncer.
Client-side Connection Pooling Deep Dive
Collab between Connection Pools and Thread Pools
Follow up on the previous section, it is essential to understand how the application usually manages the connection pool effectively.
A common pattern used in I/O-intensive applications is to leverage thread pools to handle concurrent database operations. Its primary idea is to decouple the execution of database queries from the main application thread, allowing multiple queries to be executed concurrently without blocking the main thread.
Understanding the collaboration between connection pools and thread pools is crucial for optimizing and stabilizing the application’s performance. Here is how they work together:
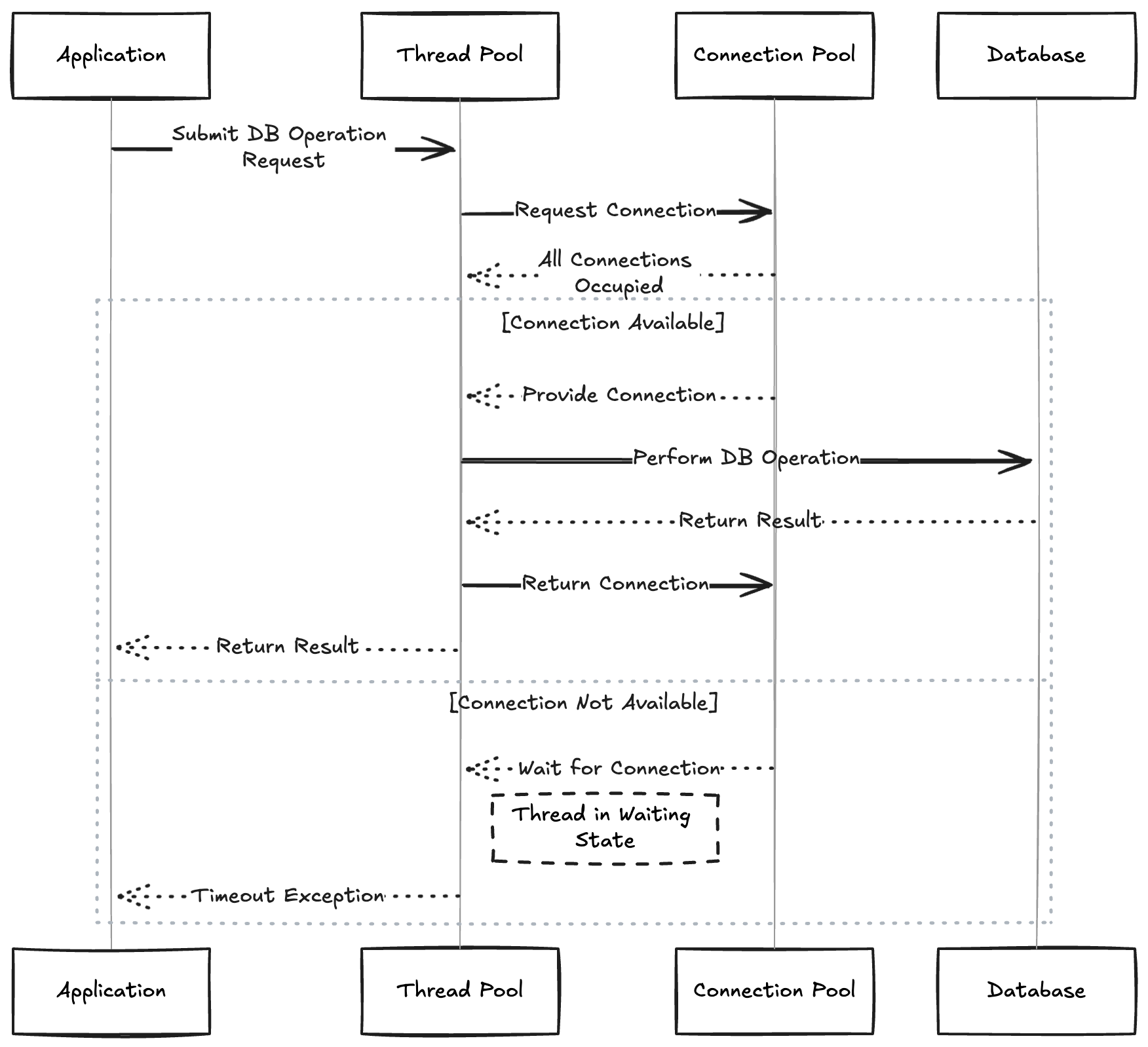
Client-side Connection Pooling and Thread Pooling
- Request Handling: A thread from the thread pool picks up an incoming request that requires a database operation.
- Connection Checkout: The thread requests a database connection from the connection pool.
- Operation Execution: The thread uses the checked-out connection to execute the required database operations (e.g., queries, updates).
- Connection Return: After completing the database operations, the thread returns the connection to the connection pool.
- Thread Availability: The thread becomes available again in the thread pool to handle new incoming tasks.
By seamlessly working together, the collaboration opens up benefits as mentioned earlier, however, this also introduces challenges maintaining the application. Let’s walk through some common faced issues and key configurable parameters of a connection pool to adjust.
Common issues with Client-side Connection Pooling
Depends on connection pool implementation, parameter names may vary, but the concept remains the same. Here are some common patterns that you may encounter when configuring a client-side connection pool, the below ones are from SQLALchemy library, you can find similar ideas in other libraries:
Connection Leaks
Connection leaks occur when connections are not properly returned to the pool after use, leading to resource exhaustion. To avoid this in SQLAlchemy:
- Use the
pool_pre_pingparameter: This checks if a connection is valid before using it, ensuring that leaked or stale connections are detected and handled. - Enable recycle: Specifying a number for the
pool_recycleparameter can ensure that connections are refreshed periodically, instead of keeping them last internally, reducing the chances of stale connections leading to leaks.
Idle Connection Timeouts
Idle connections can consume resources unnecessarily and lead to errors if the database server closes them while they’re still in the pool. Consequently, incoming requests may fall into a black hole of waiting in thread pools to check out connections. To mitigate this:
- Configure
timeout: Setting this value can help manage idle connections by automatically closing them after a specified period of inactivity. - Use
pool_recycle: this parameter ensures that connections are periodically refreshed, reducing the impact of idle timeouts.
Concurrency Issues
High concurrency can strain the connection pool, causing delays and increasing response times if the pool size is not properly configured.
- Adjust
pool_sizeandmax_overflow: pool_size sets the number of connections in the pool, whilemax_overflowallows for temporary connections when the pool is exhausted. Tuning these parameters based on your application’s concurrency needs can help prevent bottlenecks. - Set
pool_timeout: This parameter controls how long a thread will wait for a connection checkout before raising an error. Properly configuring this can help manage high-concurrency scenarios by ensuring that the application handles waiting gracefully.
Conclusion
Grasping the art of connection pooling is key to squeezing the best performance out of your database and keeping your application humming along smoothly. By carefully tuning pool parameters and staying alert to common issues, you can fully leverage the benefits of connection pooling while avoiding potential pitfalls. And let’s face it and keep an eye on your configuration in production.